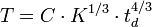Muchas veces se habran preguntado como un Ingeniero ,un Tecnico ,un estudiante o persona que trabaje en la elaboración de un sotware, puede estimar costos para poder venderlo.
Para esta tarea que es algo dispendiosa existen varios metodos entre los cuales encontramos:
1- LA OPINION DE EXPERTOS:
Esta técnica consiste en la “adivinación” basada en la experiencia personal.
2- ESTIMACIÒN POR ANALOGIA:
En esta técnica se compara el proyecto a desarrollar con uno o más proyectos terminados en función de las semejanzas y diferencias si deduce el costo del nuevo desarrollo.
3- POR DESCOMPOSICION:
Consiste en desplazar el producto que se va a desarrollar en sus componentes hasta el nivel de detalle tal que se pueda estimar el costo de cada uno de ellos. el costo total será la suma de cada uno de estas estimaciones.
4- ECUACIONES O MODELOS DE ESTIMACIÒN:
Son fórmulas matemáticas que relacionan los diversos parámetros del proyecto con el costo o esfuerzo requerido.
Ejemplo:
Software COCOMO(Parte 01).
Software SLIM.(Parte 02).
EL MODELO COCOMO(Parte 01)
El MODELO CONSTRUCTIVO DE COSTOS o COCOMO, por su acrónimo del inglés (COnstructive COst MOdel) es un modelo matemático de base empírica utilizado para estimación de costos de software que Incluye tres sub modelos, cada uno ofrece un nivel de detalle y aproximación, cada vez mayor, a medida que avanza el proceso de desarrollo del software : Básico , intermedio y detallado.
Este modelo fue desarrollado por Barry W. Boehm a finales de los años 70 y comienzos de los 80, exponiéndolo detalladamente en su libro "Software Engineering Economics" (Prentice-Hall, 1981).
CARACTERISTICAS
Pertenece a la categoría de modelos de subestimaciones basados en estimaciones matemáticas. Está orientado a la magnitud del producto final, midiendo el "tamaño" del proyecto, en líneas de código principalmente.
INCONVENIENTES
- Los resultados no son proporcionales a las tareas de gestión ya que no tiene en cuenta los recursos necesarios para realizarlas.
- Se puede desviar de la realidad si se indica mal el porcentaje de líneas de comentarios en el código fuente.
- Es un tanto subjetivo, puesto que está basado en estimaciones y parámetros que pueden ser "vistos" de distinta manera por distintos analistas que usen el método.
- Se miden los costes del producto, de acuerdo a su tamaño y otras características, pero no la productividad.
- La medición por líneas de código no es válida para modelos de orientados a objetos.
- Utilizar este modelo puede resultar un poco complicado, en comparación con otros métodos (que también sólo estiman).
MODELO DE ESTIMACIÒN
La ecuaciones que se utilizan en los tres modelos son:
- E = a(Kl)b * m(X), en persona-mes
- Tdev = c(E)d, en meses
- P = E / Tdev, en personas
donde:
- E es el esfuerzo requerido por el proyecto, en persona-mes
- Tdev es el tiempo requerido por el proyecto, en meses
- P es el número de personas requerido por el proyecto
- a, b, c y d son constantes con valores definidos en una tabla, según cada submodelo
- Kl es la cantidad de líneas de código, en miles.
- m(X) Es un multiplicador que depende de 15 atributos.
A la vez, cada submodelo también se divide en
modos que representan el tipo de proyecto, y puede ser:
- modo orgánico: un pequeño grupo de programadores experimentados desarrollan software en un entorno familiar. El tamaño del software varía desde unos pocos miles de líneas (tamaño pequeño) a unas decenas de miles (medio).
- modo semilibre o semiencajado: corresponde a un esquema intermedio entre el orgánico y el rígido; el grupo de desarrollo puede incluir una mezcla de personas experimentadas y no experimentadas.
- modo rígido o empotrado: el proyecto tiene fuertes restricciones, que pueden estar relacionadas con la funcionalidad y/o pueden ser técnicas. El problema a resolver es único y es difícil basarse en la experiencia, puesto que puede no haberla.
MODELO BASICO
Se utiliza para obtener una primera aproximación rápida del esfuerzo, y hace uso de la siguiente tabla de constantes para calcular distintos aspectos de costes:
| MODO | a | b | c | d |
| Orgánico | 2.40 | 1.05 | 2.50 | 0.38 |
| Semilibre | 3.00 | 1.12 | 2.50 | 0.35 |
| Rígido | 3.60 | 1.20 | 2.50 | 0.32 |
Estos valores son para las fórmulas:
- Personas necesarias por mes para llevar adelante el proyecto (MM) = a*(Klb)
- Tiempo de desarrollo del proyecto (TDEV) = c*(MMd)
- Personas necesarias para realizar el proyecto (CosteH) = MM/TDEV
- Costo total del proyecto (CosteM) = CosteH * Salario medio entre los programadores y analistas.
Se puede observar que a medida que aumenta la complejidad del proyecto (modo), las constantes aumentan de 2.4 a 3.6, que corresponde a un incremento del esfuerzo del personal. Hay que utilizar con mucho cuidado el modelo básico puesto que se obvian muchas características del entorno
MODELO INTERMEDIO
Este añade al modelo básico quince modificadores opcionales para tener en cuenta en el entorno de trabajo, incrementando así la precisión de la estimación.
Para este ajuste, al resultado de la fórmula general se lo multiplica por el coeficiente surgido de aplicar los atributos que se decidan utilizar.
Los valores de las constantes a reemplazar en la fórmula son:
| MODO | a | b |
| Orgánico | 3.20 | 1.05 |
| Semilibre | 3.00 | 1.12 |
| Rígido | 2.80 | 1.20 |
Se puede observar que los exponentes son los mismos que los del modelo básico, confirmando el papel que representa el tamaño; mientras que los coeficientes de los modos orgánico y rígido han cambiado, para mantener el equilibrio alrededor del semilibre con respecto al efecto multiplicador de los atributos de coste.
ATRIBUTOS
Cada atributo se cuantifica para un entorno de proyecto. La escala es
muy bajo -
bajo -
nominal -
alto -
muy alto -
extremadamente alto. Dependiendo de la calificación de cada atributo, se asigna un valor para usar de multiplicador en la fórmula (por ejemplo, si para un proyecto el atributo
DATA es calificado como
muy alto, el resultado de la fórmula debe ser multiplicado por 1000).
El significado de los atributos es el siguiente, según su tipo:
- De software
- RELY: garantía de funcionamiento requerida al software. Indica las posibles consecuencias para el usuario en el caso que existan defectos en el producto. Va desde la sola inconveniencia de corregir un fallo (muy bajo) hasta la posible pérdida de vidas humanas (extremadamente alto, software de alta criticidad).
- DATA: tamaño de la base de datos en relación con el tamaño del programa. El valor del modificador se define por la relación: D / K, donde D corresponde al tamaño de la base de datos en bytes y K es el tamaño del programa en cantidad de líneas de código.
- CPLX: representa la complejidad del producto.
- De hardware
- TIME: limitaciones en el porcentaje del uso de la CPU.
- STOR: limitaciones en el porcentaje del uso de la memoria.
- VIRT: volatilidad de la máquina virtual.
- TURN: tiempo de respuesta requerido.
- De personal
- ACAP: calificación de los analistas.
- AEXP: experiencia del personal en aplicaciones similares.
- PCAP: calificación de los programadores.
- VEXP: experiencia del personal en la máquina virtual.
- LEXP: experiencia en el lenguaje de programación a usar.
- De proyecto
- MODP: uso de prácticas modernas de programación.
- TOOL: uso de herramientas de desarrollo de software.
- SCED: limitaciones en el cumplimiento de la planificación.
El valor de cada atributo, de acuerdo a su calificación, se muestra en la siguiente tabla:
| Atributos | Valor |
| Muy bajo | Bajo | Nominal | Alto | Muy alto | Extra alto |
| Atributos de software |
| Fiabilidad | 0,75 | 0,88 | 1,00 | 1,15 | 1,40 |
|
| Tamaño de Base de datos |
| 0,94 | 1,00 | 1,08 | 1,16 |
|
| Complejidad | 0,70 | 0,85 | 1,00 | 1,15 | 1,30 | 1,65 |
| Atributos de hardware |
| Restricciones de tiempo de ejecución |
|
| 1,00 | 1,11 | 1,30 | 1,66 |
| Restricciones de memoria virtual |
|
| 1,00 | 1,06 | 1,21 | 1,56 |
| Volatilidad de la máquina virtual |
| 0,87 | 1,00 | 1,15 | 1,30 |
|
| Tiempo de respuesta |
| 0,87 | 1,00 | 1,07 | 1,15 |
|
| Atributos de personal |
| Capacidad de análisis | 1,46 | 1,19 | 1,00 | 0,86 | 0,71 |
|
| Experiencia en la aplicación | 1,29 | 1,13 | 1,00 | 0,91 | 0,82 |
|
| Calidad de los programadores | 1,42 | 1,17 | 1,00 | 0,86 | 0,70 |
|
| Experiencia en la máquina virtual | 1,21 | 1,10 | 1,00 | 0,90 |
|
|
| Experiencia en el lenguaje | 1,14 | 1,07 | 1,00 | 0,95 |
|
|
| Atributos del proyecto |
| Técnicas actualizadas de programación | 1,24 | 1,10 | 1,00 | 0,91 | 0,82 |
|
| Utilización de herramientas de software | 1,24 | 1,10 | 1,00 | 0,91 | 0,83 |
|
| Restricciones de tiempo de desarrollo | 1,22 | 1,08 | 1,00 | 1,04 | 1,10 |
|
MODELO DETALLADO
Presenta principalmente dos mejoras respecto al anterior:
- Los factores correspondientes a los atributos son sensibles o dependientes de la fase sobre la que se realizan las estimaciones. Aspectos tales como la experiencia en la aplicación, utilización de herramientas de software, etc., tienen mayor influencia en unas fases que en otras, y además van variando de una etapa a otra.
- Establece una jerarquía de tres niveles de productos, de forma que los aspectos que representan gran variación a bajo nivel, se consideran a nivel módulo, los que representan pocas variaciones, a nivel de subsistema; y los restantes son considerados a nivel sistema.
Para mas informacion en este link:
the website of COCOMOII
http://sunset.usc.edu/csse/research/COCOMOII/cocomo_main.html
Mas informacion en mi Facebook link : http://www.facebook.com/edisonpin9